Keystroke dynamics verification in a browser using JavaScript
A long time ago in the minds of many tinkerers, an idea about how everyone has an inherently unique style of typing was born.
You know uniqueness is very hard to prove or produce in Computer Science?
Seems like it’s right there behind our fingertips, and it is not as intrusive and privacy revealing as iris, face, or fingerprint scan.
If you don’t think uniqueness is a big deal just look at Bitcoin addresses implementation. They scaled the whole system to 10^77 which is almost the number of all the atoms in the observable Universe, just to avoid collisions and provide uniqueness to each new address in the network!
What’s so unique with the typing style we all have, you might ask? Same with your handwriting. It’s your brain. There is no need for math to explain this one since it’s conditionally modeled by the physical universe over time with many factors like environment, DNA and habits included. We don’t know how unique our brains exactly are to be able to quantify it. Still, we will take this basic assumption as true and that our styles can be unique enough for the purpose of this experiment, just like styles can be learned to conform to certain criteria through education.
But it’s not just that, the style may vary depending on the keyboard a person might use (mechanical, flat, etc…), a person being sleepy or typing under low light, or even being intoxicated! We will try to take all this into account later when we think about our strategic approach.
Of course, when I came across this same idea I was late to the party as there were already some academic papers explaining how it could be done in theory and discussing different approaches. Later on, I discovered some attempts to verify users’ typing style but with a lot of limitations. We will discuss what those limitations are and how to potentially overcome them.
All datasets in the wild were just big collections of many subjects and attempts recorded in sessions over days. This means there is a lot of data for each subject (over 400). At that time I read a nice approach to quantifying those inputs and arranging a good dataset to start.
There was just one problem… well more than one.
- the first thing I found was that most input capturing was done using native Window object to capture character input in Unix environment,
- the dataset was already pre-collected and hard to recreate due to hardware limitations,
- it requires MANY examples to work.
Choosing the approach
So let’s talk about our approach now that we saw what has been done so far. We will use features that are already proven to be consistent:
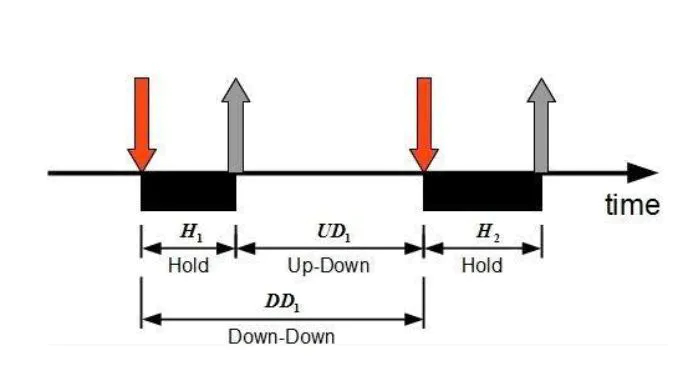
The 3 most widely used features for keystroke dynamics are:
Hold time – time between press and release of a key.
Keydown – Keydown time – time between the pressing of consecutive keys.
Keyup-Keydown time – time between the release of one key and the press of the next key.
And here is how the dataset looks:
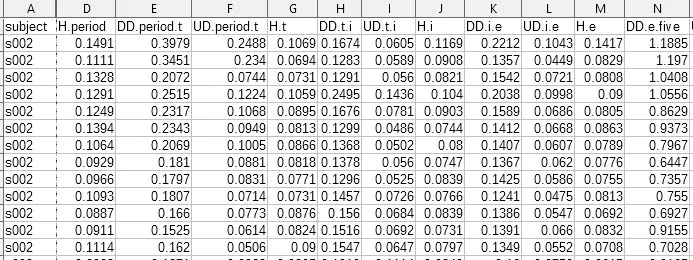
This type of problem can be described as an anomaly detection problem which is a known field in Computer Science and Machine Learning.
This means we are looking for anomalies in a sample by comparing it to existing positive samples only.
We want just a small amount of data because we don’t want to bother users too much and scare them away.
Finding suitable algorithm
Some of the research was testing algorithms like Manhattan Distance, SVM, Gaussian distribution, etc. One of the best performing so far on this task was One-Class SVM.
You can check the python code implementation in this repo.
We want to collect only one class, meaning we want to be able to have predictions based only on positive examples.
Also, we want to be able to create datasets without requiring exclusively Unix terminal to do so… no offense (PoPOS user here)
How about we make it in work the browser… I guess nobody has thought of that (probably because it’s stupid).
So, anyway, welcome JavaScript!
Wait! Is there even a JavaScript implementation of One-Class SVM? If there isn’t, I have to write one myself… which is sub-optimal!
What other algorithms can help us here that can be easily written in JS?
After some research, there seems to be some light at the end of the tunnel.
Kernel Density Estimator
As Matthew Conlen puts it nicely on his amazing webpage:
“Kernel density estimation is a really useful statistical tool with an intimidating name. Often shortened to KDE, it’s a technique that lets you create a smooth curve given a set of data.”
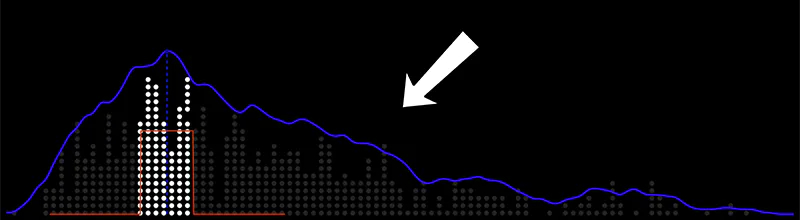
So we can have a curve representing the density of our collected data and if we apply this we get a smooth linear curve much like a signature, describing underlying data.
It would look something like this:
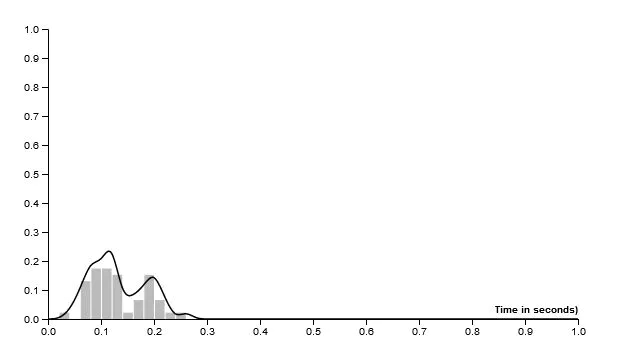
Now we can see our signature curve for each sample. It is important to be able to visualize and see how it’s just a tiny bit different for every entry.
We need to compare a new test sample with other stored signatures and decide if it fits the curve, or if it is highly likely this is you typing right now, and not someone else.
Cosine Similarity
It’s all about the arrays. What we ended up with are many arrays to compare and analyze the similarities between them.
Similarity measure refers to distance with dimensions representing features of the data object, in a dataset. If this distance is less, there will be a high degree of similarity, but when the distance is large, there will be a low degree of similarity.
Cosine similarity is a perfect way to compare arrays because it gives us probabilities and can be done in JavaScript fairly easily.
So the plan is for a user to enter his name or email at least 4 times.
We will then test if the data entered has any big outliers in itself — meaning how good and coherent is the master dataset.
We will do this by comparing the entered signatures if they match among themselves.
If correctness is 0% we should redo it with new signatures.
If samples are comparable among themselves then we can say it’s a good match for our master signature.
How do we go now from collecting a small sample size set as our master dataset to inference/prediction?
We will try to match new sample signatures to others existing in the master dataset. If the median of all cosine similarities between a test sample and each master sample is above 0.98 we can consider the provided sample to be valid.
This threshold number is arbitrary and can be set to be as high or low as necessary.
How good is this solution?
You can test it out yourself here!
Practical examples from the original idea:
- As a 2FA method – before reaching out to SMS or email, something like https://www.typingdna.com/
- As a Master Password – Together with a browser password manager, where you only type out your email to confirm password autofill from the manager.
- For document signing – attaching a signature to a document to attest ownership.
- Medical application – using this simple tool to track user typing deterioration rate to search for precursors of neural or degenerative diseases with aging.
Remaking keystroke dynamics in a browser was great fun and a nice learning experience. Hope you will get inspired to try something on your own.
Until next time.